The following is computed (in buffers).
| (W4) |
| (W5) |
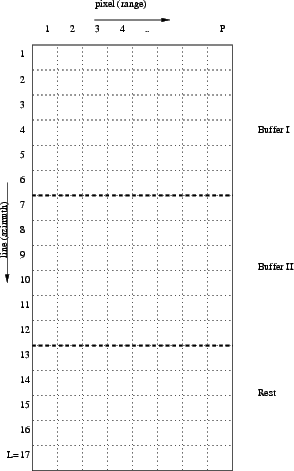
See Figure 23.2 for an explanation of the use of buffers in the implementation. In this example, the number of lines equals 17. The number of pixels equals P. Suppose multilook factor in line direction mL=3 and in pixel direction mP=3. Furthermore, after computing the available memory, the number of lines of one buffer (BL) is maximum 7. BL is set to a multiple of mL, BL=6.
Now the number of fully filled buffers NB = 17/6 = 2. The number of lines left in the last buffer equals 17We can compute something in this last buffer only for the first three lines, so the last buffer is 3 lines long.
The first buffer is read (master and slave image), and computations are performed. These results are written to disk. Then next buffer, etc. If buffers==3 then resize the matrices for the computations.
The number of lines of the total result are L/mL and P/mP (floored).